BÜYÜK VERİ KÜMELERİNDE KARAR AĞACI
BÜYÜK
VERİ KÜMELERİNDE
KARAR AĞACI
(Decision Tree in
Very Large Data Sets)
|
Alper Şahin ÖNER- KIRIKKALE ÜNİVERSİTESİ
BİLGİSAYAR MÜHENDİSİ
alpersahinoner@gmail.com
Özet
Sınıflandırma,veri
kümelerini birbirinden ayrı tanımlayıp bir model ortaya çıkarma işidir.Bu
ayırmanın yapılması için modeller kullanılır.Bu yöntemlerden biri olan karar
ağacı indüksiyonunda bu sınıflandırmayı yapmak mümkündür.Fakat veri
kümelerimizin boyutu arttığında veri kümesine göz atmak çok zaman alıcı
olacaktır.Bu yüzden, veri kümesini kullanacağınız bir biçimde hazırlamak ve
veri alanları hakkında daha doğru sonuçlar çıkarmak için bir ajan
yerlestirilecek ve veri kümesinin verilerine bağlı olarak, sınıflar için göze
çarpan kategorileri ajanımız seçicektir.[1]
Ayrıca makalede,veri kümesinden ajanımızın kategorik seçim kurallarını
oluşturup eğitim setini oluşturmaya yönelik bir yaklaşımı açıklamaktadır.
1-Giriş
Gün geçtikçe veri setlerimiz oldukça
büyüyor veya daha iyi sonuçlar almak için veri setlerini büyütüyoruz.Ama ne
kadar veri setlerini büyütsekte çok büyük veri kümelerine veri madenciliği
uygulamak her satırın kontrolü,ifade edilmesi oldukça zaman alıcıdır.Kullanıcılar,görüntülenecek
bir veri kümesinin ihtiyacı olanı veya daha belirgin olan özelliklerini
belirleyerek göze çarpan kavram örneklerinden sonuçlar
çıkartabilir.Sınıflandırma yapıtığımız karar ağacında bu veri kümesini
bölümleyerek (n bölüme m tane paralel bölüm şeklinde) karar ağaçları
oluşturulur.Oluşturulan birden çok karar ağaçları Chan ve Stolfo’nun
çalışmalarından[2,3] yararlanılarak birleştirilir.Bu birleştirme bazı kurallara
göre birleştirilir.
Amacımız, birden fazla oluşan ağacı
belirli kurallara göre ayırıp birleştirmektir.Bu ajanımız ise verilerin n alt
kümelerinde bağımsız olarak yapıldıktan sonra tek bir karar sistemine sahip
olmaya çalışmasıdır[1].Burada kullanacağım C4.5 algoritması büyük veri setlerini için kullanılmaktadır.
2-KARAR AĞAÇLARI
VE KARAR AĞACI ALGORİTMA
Karar ağaçları, sınıflandırma ve tahmin
için sıkça kullanılan bir veri madenciliği yaklaşımıdır.
Karar ağaçları;
• Düşük maliyetli olması,
• Anlaşılmasının, yorumlanmasının ve veri
tabanları ile entegrasyonun kolaylığı,
• Güvenilirliklerinin iyi olması
gibi nedenlerden ötürü en yaygın kullanılan sınıflandırma tekniklerinden
biridir.[4]
Büyük veri seti için C4.5 daha doğru sonuçlar için C5.0 algoritması
kullanılır.
3-C4.5 VE C5.0 ALGORİTMASI
Algoritmalarda,her düğümden çıkan çoklu
dallar ile ağaç oluşturur.Algoritmalar büyük veritabanlarına karşı
kullınılır.Ayrıca dalların sayısı bilinmeyen nitelik değerlerinin sayısına
eşittir.Tek bir sınıflayıcı da birden çok karar ağacını birleştirir. Ayırma
işlemi için bilgi kazancı kullanır.Budama işlemi her yapraktaki hata oranına
dayanır.Hafızanın %90 oranda iyileştirildiği gözlemlenmiştir.Kurallar ile
kurulan algoritmada eğer eğitim setindeki tüm kayıtlar özdeş olarak
işleniyorsa,kuralın sol tarafını daha basit
benzerlikte ola ile değiştirmektedir.
4-VERİ SETİNİ
BÖLME VE KURALLARIN BELİRLENMESİ
Karar ağacında her düğümde bir öznitelik
ve her dal testin sonucunu gösterir.Biz burada C4.5 yola cıkarak öğrenme kümesi
ve veri setindeki en ayırt edici özellik belirlenerek ağacın kökü olarak
alınır.
C4.5 gibi karar ağacı algoritmalarında
en ayırt edici özelliklerin belirlenmesi için Bilgi Kazancı(Information Gain) hesaplanır.Bilgi Kazancının
hesaplanmasında Entropi
kullanılır.Entropi sistemdeki belirsizliğin ve düzensizliği ölmek için bulunur.[4]

#Formül
-2
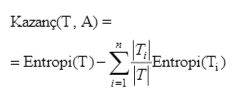
Bir veri
setinin {C1,C2,....,Ck} şeklinde birden fazla sınıftan oluştuğunu ve
T’nin sınıf
değerlerini
gösterdiğini düşündüğümüzde, bir sınıfa ait olasılık Pi=(Ci/|T|) olur ve
sınıflara
ait entropi
Formül 1 ile hesaplanır.[6]
Veri
setindeki A özniteliğine göre T sınıfının değerleri T1,T2,...,Tn şeklinde alt
kümelere ayrıldığını
varsayalım.Aöznitelik değerleri
kullanılarak T sınıf
değerlerinin bölünmesi
sonucunda
elde edeceğimiz kazancı hesaplamak için Formül 2 kullanılır.[4]
T kümesi
için A özniteliğinin değerini
belirlemek için Formül 3
ile hesaplanan bölümleme bilgisi
kullanılır.
#Formül -3

Son olarak,kazanç oranı Formül 4 ile
elde edilir. Kazanç
oranı,sınıflandırma işlemindekullanacağımız ayırma
ile elde edilen
bilgi oranını verir. Kazanç oranı
en yüksek olan öznitelik,
dallanma için tercih edilecek nitelik olacaktır.[4]
#Formül -4

Ağacın çocuk
düğümü olan A düğümüne ait alt veri kümesi belirlenir.Her
alt küme için
ekrar bilgi kazancı hesaplanarak en ayırt edici özellik belirlenir.Bu işlemler
her düğüm için
aşağıdaki durumlardan biri oluşuncaya
kadar devam eder:
ü Örneklerin hepsinin aynı sınıfa
aitolması
ü Örnekleri bölecek
özellik kalmamış olması
ü Kalan özelliklerin
değerini taşıyan örnek bulunmaması[4]
5-BİRLEŞTİRME
VE SONUÇ
Oluşturulan
ağaçlar birbirleriyle ilişkişi olan kurallara göre birleştirme
yapılacaktır.Birleştirme benzer koşullarda sorulan dallar aynı olarak kabul
edilecek ve ağaçların ucu benzer olana göre birleştirme yapılacaktır. Karar ağacının
oluşturulmasından sonra, Budama işlemi ile
karar ağacının sınıflandırma doğruluğunu
etkilemeyen veya katkısı olmayan
bölümleri çıkartılır.Böylece gürültülü
veriler elenmiş,daha başarılı ve
karmaşıklığı daha az
olan bir ağaç elde edilmiş olur.
Kaynaklar
[1]. ‘’Decision Tree Learning on
Very Large Data Sets’’. https://www.researchgate.net/publication/3776339_Decision_tree_learning_on_very_large_data_sets
[2] L. Breiman, J.H.
Friedman, R.A. Olshen, P.J. Stone,
Classification and Regression Trees, Wadsworth In-
ternational Group, Belmont, CA. 1984.
[3] P. Chan and S. Stolfo, “Sharing
learned models
among remote database partitions by local meta-
learning”, Proceedings Second International Con-
ference on Knowledge Discovery and Data Mining,
pp. 2-7, 1996.
[4]. Aslı ÇALIŞ, Sema KAYAPINAR*,
Tahsin ÇETİNYOKUŞ.10 Eylül 2014. “Veri madenciliğinde karar ağacı algoritmaları
ile bilgisayar ve internet güvenliği üzerine bir uygulama” Gazi Üniversitesi Endüstri Mühendisliði Dergisi,
Cilt: 25 Sayý: 3-4 Sayfa: (2-19). https://www.mmo.org.tr/sites/default/files/ab225c69b017f13_ek.pdf



Yorumlar
Yorum Gönder